Core PDML Specification
|
Version |
2.0.0 |
|
Latest update |
2025-03-25 |
|
First published |
2021-06-13 |
|
Website |
|
|
Author |
Christian Neumanns |
|
Copyright © 2019-2025 |
Christian Neumanns |
Introduction
The Practical Data and Markup Language (PDML) is a text format designed for encoding data and markup (i.e. formatted text).
This document is divided into two parts:
-
Part I: Specification: provides the Core PDML rules for encoding data and markup as plain text.
The specification is written for anyone who wants to know the exact rules governing the PDML text format (e.g. software developers who want to implement a PDML parser, an editor/IDE plugin, or other PDML assets).
-
Part II: Usage and Implementation Guidelines: provides practical tips for using and implementing Core PDML.
Note
Readers are supposed to be familiar with common technical IT terms such as Unicode and abstract syntax tree (AST).
For general information about PDML you may read PDML Overview.
Before reading the specification, you might also want to first see some Core PDML Examples, to get an idea of how data and markup are encoded in PDML.
Part I: Specification
This part provides the authoritative specification for Core PDML, encompassing the fundamental set of simple rules needed for encoding data and markup of any complexity as plain text. This is the minimum set of rules that every PDML implementation must conform to.
PDML Extensions (optional features designed to enrich the Core PDML functionality) are not covered here. The difference between Core PDML and PDML Extensions is explained in What Is "Core PDML" and What Are "PDML Extensions"?.
Note
PDML syntax rules are shown in Extended Backus–Naur form (EBNF) notation.
Overview
In this chapter you'll be presented with a birds-eye view of Core PDML, in order to become acquainted with its terminology and rules, and grasp a general understanding. Throughout the following chapters, each element will be explained in full detail. You may skip this chapter if you're already familiar with the basic Core PDML concepts.
A PDML document is structured as a tree that can contain three types of nodes:
-
This node has a tag (aka label or name) and one or more child nodes.
A tag is a sequence of one or more Unicode code points (e.g.
config,chapter).Each child node can be anyone of the three node types.
Syntax:
"[" tag separator node + "]"The separator can be a space, tab, or line break.
ExampleYou can use tagged branch nodes, for instance, to encode a record (aka structure, struct, or compound data). Here's a simple example of a node tagged
dimensionscontaining two child-nodes, the first taggedwidthand the second oneheight:[dimensions [width 200][height 100]]In other words, the above code represents a record (tagged
dimensions) with two fields:widthandheight. Each field is a key–value pair. In our example, the keywidthcontains the value200).We can enhance readability by indenting nested nodes:
[dimensions [width 200] [height 100] ]In XML, the semantically equivalent tree looks like this:
<dimensions> <width>200</width> <height>100</height> </dimensions>And here's the same data structure expressed in JSON:
{ "dimensions": { "width": 200, "height": 100 } } -
This node has a tag, but no child nodes.
Syntax:
"[" tag "]"ExampleTagged leaf nodes are used to encode record fields that have no value (aka "absence of value";
null,nil,nothing,voidin programming languages).Suppose that a user didn't enter a value for field
remarkin a data entry form. Then the code representing this field (i.e. its key–value pair) would look like this:PDML:
[remark]XML:
<remark></remark>or<remark />JSON:
{ "remark": null }Besides being used for record fields with no values, tagged leaf nodes are also useful to represent native elements, especially in markup documents.
For example, a horizontal rule (hr) in a markup document would be inserted using the following syntax:
PDML:
[hr]HTML:
<hr />or<hr> -
This node is composed of text (Unicode code points), and it doesn't have a tag.
ExampleUntagged text leaf node:
Lorem ipsum ...An untagged text leaf is always contained in a tagged branch node. Here's a branch node tagged
p(paragraph) containing the untagged text leafLorem ipsum ...:PDML:
[p Lorem ipsum ...]HTML:
<p>Lorem ipsum ...</p>
The root node of a PDML document must be a tagged branch node or a tagged leaf node.
Here's a PDML document containing a mixture of data and markup code:
[document
[data
[message
[id 123]
[content All is well! 👍]
[public? yes]
[remark]
]
]
[markup_code
[p We can write text in [b bold], [i italic], or [b [i bold and italic]].]
]
]The following image shows the tree structure of node data, stripped of indentation:
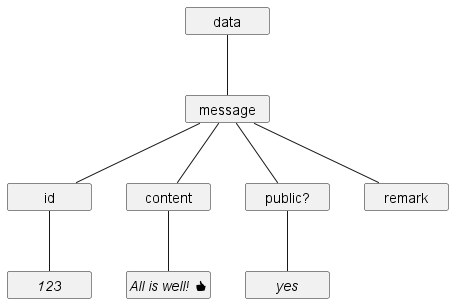
A PDML document is structured in a way that resembles the tree of directories and files on your PC.
To help you grasp the essence of PDML terminology, the following analogies may prove useful:
-
A directory containing other directories and/or files is like a tagged branch node in PDML: It has a name (called tag in PDML) and child-nodes.
-
An empty directory is like a tagged leaf node in PDML: It only has a name (a tag).
-
A non-empty text file is like an untagged text leaf node in PDML: It contains a sequence of one or more characters. However, while a file has a name, an untagged text leaf has no tag.
Basic PDML Terminology
Some commonly used IT-terms are defined as follows in the context of PDML:
-
Character
A single Unicode code point.
Examples:
a,Z,é,日,0,9,!,😀 -
Text
A sequence of one or more characters.
Examples:
Hello,Guten Tag!,やあ,a = b + 1 -
Whitespace character
Any one of the following characters:
Unicode Code Point Unicode Name C-style Syntax U+0009 Character Tabulation (HT, TAB) '\t' U+000A End of Line (EOL, LF, NL) '\n' U+000C Form Feed (FF) '\f' U+000D Carriage Return (CR) '\r' U+0020 Space (SP) ' ' -
Whitespace
A sequence of one or more whitespace characters.
-
Line break
One of the following:
-
LF: a single End of Line character (U+000A), also called Unix/Linux line break -
CRLF: a sequence of a single Carriage Return character (U+000D) followed by a single End of Line character (+U000A), also called Windows/DOS line break
-
Tree Structure
As mentioned in Overview, a PDML document is structured as a tree that can contain three types of nodes:
-
Tagged Branch Node: has a tag and one or more child nodes.
A child node can be anyone of the three node types.
-
Tagged Leaf Node: has a tag, but no child nodes.
-
Untagged Text Leaf Node: is composed of text.
The root node must be a tagged branch node or a tagged leaf node.
Note
PDML is a text format, and this specification describes the rules for encoding PDML documents as plain text — typically represented as a sequence of Unicode code points stored in a UTF-8 encoded text file bearing the .pdml extension.
Beyond text encoding, there are other methods for storing PDML documents, but they are not covered here. For example, a PDML parser typically stores a PDML document in an abstract or concrete syntax tree (AST or CST). These data structures are implementation- and programming-language-dependant, and beyond the scope of this specification.
Tag
Each tagged node (i.e. tagged branch node or tagged leaf node) must have a tag (aka label, name).
A tag is composed of arbitrary text.
Some characters are not allowed (see Invalid Characters). Moreover, some characters must be escaped (see Character Escape Sequences).
A node tag does not need to be unique. Distinct nodes in a tree may have the same tag, even if they are siblings.
Here are a few tag examples:
quality
Qualität // German for "quality"
คุณภาพ // Thai for "quality"
text_color
list.index-a
123
2d_point
2025-01-07
_
😍 // Unicode emoticonTags may contain whitespace characters, but they must be escaped (see Character Escape Sequences).
For example, the tag Net Weight contains a space character which must be replaced with its escape sequence \s:
Net\sWeightAnd this tag, which contains also a line break and square brackets (in addition to a space):
Net Weight
[kg]... must be written:
Net\sWeight\n\[kg\]Tagged Branch Node
A tagged branch node (also simply called branch node) is composed of a tag, a separator, and a list of one or more child nodes.
Syntax
The syntax of a tagged branch node is as follows:
"[" tag separator node + "]"A tagged branch node is enclosed by a pair of square brackets ([...]) which serve as node delimiters: the node starts with an opening delimiter [ and ends with a closing delimiter ]. Note that a Tagged Leaf Node is also enclosed by a pair of square brackets, but an Untagged Text Leaf Node isn't.
The opening delimiter ([) is immediately followed by the node tag, a separator (often a single space), and one or more child nodes.
A node with tag greeting and text content (child-node) Hello world looks as follows:
[greeting Hello world]A tagged branch node containing only text (as in the example above) is called a tagged text node.
Separator
In a tagged branch node, the node tag must be separated from the child nodes (i.e. the node contents) by a valid separator.
The following separators (consisting of one or two whitespace characters) are allowed:
| Unicode Code Point(s) | Name | C-style Syntax |
|---|---|---|
| U+0020 | Space | ' ' |
| U+000A | End of Line (Unix line break) | '\n' |
| U+000D U+000A | Windows line break | "\r\n" |
| U+0009 | Character Tabulation | '\t' |
Let's look at some examples.
Here's a node tagged color with text content green, and a space used as separator:
[color green]
^If two spaces were present:
[color green]
^^... then the first space would serve as separator, while the second space would be part of the node content. In other words, the above node contains the text “ green” (i.e. the text starts with one space).
Because a line break is also a valid separator, the following two nodes are semantically equivalent:
[color green]
[color
green]Note that the line break in the second example can be a Unix/Linux line break (LF) or a Windows line break (CRLF).
Now consider the following snippet:
[color
green
]Here, the line break after color serves as separator, and the node contains a single text leaf starting with four spaces (i.e. the indentation) and ending with a line break (included).
The following example shows node b containing node i with text content huge:
[b [i huge]]
^ ^It would be invalid to omit the separator of node b:
[b[i huge]]
^ INVALID!The separator is required in tagged branch nodes.
Note that each tagged branch node has only one separator right after the tag, no matter how many child nodes it contains. Consider this snippet:
[foo [key1 value1] [key2 value2]]
^The space between the two child nodes is not a separator of the child nodes — it is an Untagged Text Leaf Node composed of a single space. Hence, node foo contains three child nodes, the second one being a single space character.
Also note that escaped whitespace characters are not eligible separators, and will be treated as part of the tag. This snippet:
[a\sb c]... represents a node with tag a b and text content c — it does not represent a node with tag a and text content b c.
Child Nodes
A tagged branch node contains a list (i.e. ordered sequence) of one or more child nodes.
A child node can be:
-
a tagged branch node (which might itself have child nodes too) (e.g.
[color green]) -
a tagged leaf node (e.g.
[remark]) -
an untagged text leaf node (e.g.
lorem ipsum ...)
Examples:
-
A branch node tagged
color, containing the textlight green:[color light green] -
A branch node containing another branch node:
[config [color light green]]Here, node
configcontains one child node, taggedcolor, containing the textlight green. -
A deeply nested tree:
[config [color light green][size [width 200][height 100]]]Node
configcontains two child nodes:colorandsize. Nodesizealso contains two child nodes:widthandheight.The above code is written using the so-called compact form. To increase readability and maintainability we can prettify it using indentation:
[config [color light green] [size [width 200] [height 100] ] ]However, note that the additional whitespace used for indenting is part of the data stored in the AST. As explained later, whitespace is preserved in PDML (as in XML, but unlike JSON and YAML). After removing the whitespace used for indentation, the tree will be equivalent to its compact form (see Insignificant Whitespace).
-
A branch node containing a mixture of text and other branch nodes:
[p We can write words in [b bold], [i italic], or [b [i bold and italic]].]In this example, PDML is used to encode markup that would be rendered as follows:
We can write words in bold, italic, or bold and italic.
Tagged Leaf Node
A tagged leaf node has only a tag, but no separator nor child nodes.
Its syntax is as follows:
"[" tag "]"Example of a tagged leaf node with tag remark:
[remark]Important
A separator is not permitted in a tagged leaf node. Hence, the following code is invalid, and the parser must generate an error:
[remark ]
^ INVALID! If two spaces were present:
[remark ]
^^... then the code would represent a Tagged Branch Node containing an Untagged Text Leaf Node consisting of a single space character.
Untagged Text Leaf Node
An untagged text leaf node (also simply called a text leaf) is composed of arbitrary text. This text is all there is to this node — there's no tag and no delimiters.
Some characters are not allowed (see Invalid Characters). Moreover, some characters must be escaped and others may be escaped (see Character Escape Sequences).
An untagged text leaf node must be contained in a tagged branch node. In other words, a text leaf is always a child of a branch node.
For example, a branch node tagged message containing the text leaf All is well! 👍 looks as follows:
[message All is well! 👍]As previously mentioned, a tagged branch node containing only text is also called a tagged text node. Hence, the above example shows a tagged text node (tagged message) containing the text leaf All is well! 👍.
Using the Thai language, the node would look like this:
[ข้อความ ทุกอย่างดี 👍]Here's a contrived example of a branch node tagged 1 containing the text leaf 2 3:
[1 2 3]The following warning node contains the text leaf: Characters \, [, ], and ^ must be escaped.:
[warning Characters \\, \[, \], and \^ must be escaped.]Invalid Characters
The following characters (Unicode code points) are invalid anywhere in a PDML document (including tags and text leaves), because they can cause readability, interpretation, and security issues.
-
C0 Controls in the range U+0000 to U+001F (included), except:
-
U+0009 (Character Tabulation)
-
U+000A (End of Line)
-
U+000C (Form Feed)
-
U+000D (Carriage Return)
-
-
C1 Controls in the range U+0080 to U+009F (included)
Tip
Unicode Escape Sequences (a PDML extension not covered here) can be used to insert the above Unicode code points (C0 Controls and C1 Controls). For example, a backspace (U+0008) can be inserted using the Unicode escape sequence \u{8}.
The only exception is U+0000, which is always invalid in PDML documents, even when written as an escape sequence. U+0000 is prohibited because many programming languages treat it as a string terminator. As a result, its inclusion within a string could cause unexpected and unpredictable malfunctions, potentially creating vulnerabilities that could be exploited maliciously.
To represent binary or non-printable data in a PDML document, encoding methods like Base64 should be used, ensuring the document remains valid, readable, and interoperable (see Encoding Binary Data).
Unicode surrogate code points in the range U+D800 to U+DFFF are also invalid anywhere in a PDML document, because they are reserved for encoding Unicode code points beyond U+FFFF in UTF-16 encodings.
Character Escape Sequences
Some characters in tags and text leaves must be escaped.
A character escape sequence starts with a backslash (\), followed by a second character that denotes the escaped character (as in C-like programming languages).
For example, the character escape sequence \t is used to escape a Character Tabulation (TAB).
The following table shows the character escape sequences:
|
PDML Category |
Unicode |
Character |
Escape |
Mandatory |
|---|---|---|---|---|
|
Escape character |
U+005C |
\ |
\\ |
yes |
|
Node delimiters |
U+005B |
[ |
\[ |
yes |
|
U+005D |
] |
\] |
yes |
|
|
Whitespace |
U+0009 |
Character Tabulation |
\t |
no |
|
U+000A |
End of Line |
\n |
no |
|
|
U+000C |
Form Feed |
\f |
no |
|
|
U+000D |
Carriage Return |
\r |
no |
|
|
U+0020 |
Space |
\s |
no |
|
|
Reserved |
U+005E |
^ |
\^ |
yes |
|
U+0028 |
( |
\( |
no |
|
|
U+0029 |
) |
\) |
no |
|
|
U+003D |
= |
\= |
no |
|
|
U+0022 |
" |
\" |
no |
|
|
U+007E |
~ |
\~ |
no |
|
|
U+007C |
| |
\| |
no |
|
|
U+003A |
: |
\: |
no |
|
|
U+002C |
, |
\, |
no |
|
|
U+0060 |
` |
\` |
no |
|
|
U+0021 |
! |
\! |
no |
|
|
U+0024 |
$ |
\$ |
no |
All characters in the above table must be escaped in tags.
However, only characters in rows marked as "yes" in the last column must be escaped in text leaves. Characters in rows marked as "no" may be escaped.
For instance:
-
The text snippet
a[1]must be written asa\[1\]in tags and in text leaves. -
The text snippet
a=bmust be written asa\=bin tags; in text leaves it can be written asa=bora\=b.
Note
The reason for having characters that may be escaped in text leaves is to support the same set of escape sequences in tags and text leaves.
This can be useful, for instance, when shared code (possibly auto-generated) is used in tags and text leaves. For example, the text snippet a\sb can be inserted into a tag as well as into a text leaf.
Escape sequences not listed in the above table are invalid and parsers must generate an error if they occur in a PDML document. For example, if \m occurs in a PDML document, the parser must generate an error — it must not convert \m to m or ignore the invalid escape sequence.
A node tagged Note (important) with text content Characters \, [, ], and ^ must be escaped. is written as follows:
[Note\s\(important\) Characters \\, \[, \], and \^ must be escaped.]Whitespace Rules
A PDML document may contain whitespace before or after the root node. Any other character is invalid (including escaped whitespace characters like \t and \n). Whitespace before or after the root node must be ignored.
Here's a valid PDML document that has one empty line before the root node, and two empty lines after it:
[root
[child text]
]
Whitespace in text leaves must be preserved by parsers.
Consider the following PDML snippet:
[a foo [b]
2 [c] [d]
]Here, node a contains seven child nodes:
-
text leaf
{space}foo{space}{space}{space} -
tagged leaf node
b -
text leaf
{line break}{space}{space}{space}{space}2{space} -
tagged leaf node
c -
text leaf
{space} -
tagged leaf node
d -
text leaf
{line break}
Note that all line breaks are stored in the AST as they are encountered, without any transformations such as normalization to LF. Hence, an AST might contain a mixture of Unix line breaks (LF) and Windows line breaks (CRLF).
Note
Preserving whitespace must be the default behavior of any PDML-compliant parser. See How to Handle Whitespace for guidelines about handling whitespace in specific contexts.
Encoding
PDML documents must be encoded in UTF-8.
Versioning
This specification adopts Semantic Versioning.
Useful Links
-
Core PDML Grammar, expressed in Extended Backus–Naur form (EBNF) notation
-
Official website: pdml-lang.dev
Glossary
Note
The following definitions are PDML-specific — they might have different definitions in other domains.
|
A single Unicode code point. Examples: |
|
|
A node contained in a tagged branch node. The child can be a tagged branch node, tagged leaf node, or untagged text leaf node. |
|
|
A Unix line break ( |
|
|
A pair of square brackets used to start and end a node ( Example: |
|
|
A space, line break, or tab that separates a tag from child nodes. Example: |
|
|
PDML AST |
An abstract syntax tree (AST) representing a PDML text document. |
|
UTF-8 text that encodes data and/or markup according to the rules of the PDML specification. Example: |
|
|
A label or name assigned to a tagged branch or tagged leaf node. Example: |
|
|
A node that has a tag, a separator, and one or more child nodes. Example: |
|
|
A node that has a tag, but no separator and no child nodes. Examples: |
|
|
A tagged branch node that contains a single text leaf. Example: |
|
|
A sequence of one or more characters (Unicode code points). Examples: |
|
|
A tagless leaf node composed of text. Example: |
|
|
A sequence of one or more whitespace characters. |
|
|
A space, tab, carriage return, line feed, or form feed. |
Part II: Usage and Implementation Guidelines
This part provides practical tips for using and implementing PDML, based on real-case scenarios that need to be considered.
The following topics are covered: length limits, tips on using tags, handling whitespace, and encoding binary data.
Length Limits
The specification does not define a length limit (i.e. maximum number of characters/Unicode points) for tags, text leaves, or the whole document. Practical limitations depend on software implementations (e.g. parsers) and should be documented.
In case of very large PDML documents, you may encounter performance issues or out-of-memory errors, depending on the capabilities of the system.
If you create a parser designed to read very large documents, consider creating a streaming parser that processes the document in smaller chunks. For example, instead of loading the whole document into memory, the parser only holds the currently parsed token in memory (e.g. a single tag or text leaf). The PDML reference implementation includes a streaming parser that uses this technique and generates events to be consumed by a handler.
Tags
Usage
A tag should shortly convey the content of the node.
Examples:
-
A node with tag
configcontaining configuration data:[config [client ...] [server ...] [shared ...] ] -
A node tagged
customerscontaining a list of customers:[customers [customer ...] [customer ...] [customer ...] ] -
Node
bookcontaining the markup of a book.[book [meta [title ...] [author ...] ] [preface ...] [chapter ...] [chapter ...] [chapter ...] ]
Length
Tags are rarely longer than 30 characters.
To ensure readability, compatibility, and performance across various tools, tags should be less than 80 characters long.
Case-Sensitivity
Whether tags are case-sensitive or not depends on the application that interprets a PDML document (according to the domain in which PDML is used).
A PDML parser isn't concerned about case-sensitivity — it simply parses each tag "as-is" and stores it in an AST (or whatever alternative data structure it employs to represent the parsed document).
Hence, tags foo, FOO, and Foo are parsed unchanged, and the target application which consumes the parsed document determines if the three tags are valid and if they are semantically equivalent or not.
Escaped Characters
Tags rarely contain characters that must be escaped (e.g. [, ], \).
If you use PDML in a context where escape sequences are required frequently, you might want to use a parser that supports Quoted String Literals (a PDML extension, not part of Core PDML, and not specified here).
Example: A node tagged Net Weight [Estimate] and content 200 must be written as follows in Core PDML:
[Net\sWeight\s\[Estimate\] 200]You can enhance readability and writeability by using a quoted string literal:
["Net Weight [Estimate]" 200]Anonymous Nodes
Sometimes a tag is irrelevant. In such cases, the convention is to use an underscore (_). You can think of an underscore-tagged node as an anonymous node.
Suppose we want to store a list of names:
[names
[name Tim]
[name Tom]
[name Tam]
]Instead of repeating name for each element, you can simply use _:
[names
[_ Tim]
[_ Tom]
[_ Tam]
]Here, _ is a valid tag, parsed and treated like any other tag. To keep the tag short you could use alternatives like n or x, or any other Unicode code point(s). However, by convention, using _ tells us that the tag is irrelevant.
Note
PDML extensions provide other ways to encode simple lists (e.g. [names Tim, Tom, Tam]), but they are not covered in this document.
How to Handle Whitespace
IT history has repeatedly proven that whitespace (though seemingly harmless) can cause unexpected results and malfunctions when handled incorrectly. Problems and unanticipated edge cases can arise due to the following factors:
-
There is no universal, precise, one-size-fits-all definition for the term whitespace in the IT world — this term can mean different things in different domains and contexts.
-
To enhance readability and maintainability, we often insert insignificant whitespace (e.g. indents) into text documents containing data or markup.
-
Line breaks are defined differently in Unix/Linux (
LF) and Windows (CRLF).Moreover, editors and other tools might silently transform line breaks (e.g.
CRLFtoLF), and these transformations depend on the tools used, the OS, as well as configuration files installed on your PC. -
Editors and other tools often render tabs as spaces, making it difficult for humans to distinguish between the two.
Software applications might also silently transform tabs to spaces, or vice versa.
To help you avoid unexpected issues, this section offers some tips for managing whitespace in PDML documents.
Basic Principles
To keep things straightforward and practical, PDML adheres to the following principles:
-
As stated in the specification, a whitespace character can be a space (SP), character tabulation (HT, TAB), carriage return (CR), end of line (EOL, LF, NL), or form feed (FF). These are the characters commonly used in data and markup documents, and it's easy to type them on a keyboard. The only exception is
FF, which is supported because it's still used in some legacy applications.Note
Unicode defines additional code points representing whitespace (over 20), but they have no special meaning in PDML — they are parsed and stored in ASTs like any other character.
-
Section Whitespace Rules states: "Whitespace in text leaves must be preserved by parsers."
This rule is justified because PDML is a general purpose and portable text format. Any attempt to define standard whitespace-handling rules would fail: the rules would be "just what we need" in some contexts, but "totally unsuited" in others.
Insignificant Whitespace
To illustrate the challenges of handling whitespace correctly in various situations, let's first consider a 2D point with coordinates x=1.234 and y=567.8. In PDML we can encode this point as follows:
[2d_point [x 1.234][y 567.8]]Here we use the so-called compact form: every character is significant and required.
Note
Whenever PDML documents are read and written only by machines, the compact form is usually preferable because it improves time- and space-efficiency.
Although the compact form is short and efficient, it can be difficult to read for humans (especially in the case of large, deeply nested trees). We can easily enhance readability and maintainability by indenting child nodes and treating the additional whitespace as insignificant:
[2d_point
[x 1.234]
[y 567.8]
]The additional whitespace is called insignificant because it doesn't change the data (semantics) — it's sole purpose is to enhance readability and maintainability (aka pretty printing, prettyfying, beautifying).
We can further enhance readability by also inserting insignificant whitespace within the x and y nodes:
[2d_point
[x 1.234]
[y 567.8 ]
]Because whitespace is preserved when the document is parsed into an AST, it must be ignored or removed in one way or another when the AST is transformed into a programming-language-dependant data structure (e.g. record) stored in memory.
Now let's look at an example of markup:
[article [title Harmonious States][p This article [i demonstrates] that ...][p You'll also discover ...]]Again, we can greatly enhance readability and show the tree structure by inserting insignificant whitespace:
[article [title Harmonious States]
[p This article [i demonstrates] that ...]
[p You'll also discover ...]
]Since paragraphs are frequently used in markup, it would be convenient to omit the p nodes and simply insert an empty line that will be interpreted as a paragraph break:
[article [title Harmonious States]
This article [i demonstrates] that ...
You'll also discover ...
]Obviously, this level of user-friendlyness requires customized whitespace-handling rules to be applied by the application reading the PDML document.
As you can see from these simple examples:
-
Insignificant whitespace is often useful because it enhances readability and maintainability, especially in cases of deeply nested PDML documents maintained by humans.
-
Sometimes whitespace is significant, sometimes it's not.
-
The rules for proper whitespace-handling can vary largely — they depend on the nature and context of the PDML documents.
For example, whitespace-handling rules for data documents are usually very different from those required for markup documents.
This implies that different rules might be required for different parts of documents that contain a mixture of data and markup.
Now that we're aware of the challenges, let's have a look at possible approaches for whitespace-handling:
The best approach (or combination of approaches) depends on the domain and context in which PDML is used. The following sections provide general guidelines.
Utility Functions and Methods
A PDML implementation may provide any number of utility functions/methods designed to apply common whitespace-handling operations. They are usually invoked by the application code after the PDML document has been parsed into an AST. They may check if whitespace is contained in a node, change the data stored in the AST, or transform AST nodes into ready-to-use values of a specific type.
Let's look at some examples (using Java syntax):
-
Method
isWhitespace()in classTextLeafNode: returnstrueif the text leaf contains only whitespace, otherwise returnsfalse.Application code can invoke code like
remarkField.isWhitespace(), and take appropriate action, such as ignoring the node if the method returnstrue. -
Method
trimTextLeafNodes()in classTaggedBranchNode: removes leading and trailing whitespace in all text leaves contained in the branch.For example, consider this structure:
[3d_point [x 123.45] [y 1.1 ] [z 3 ] ]Calling
trimTextLeafNodes()on node3d_pointtransform the structure into this one:[3d_point [x 123.45] [y 1.1] [z 3] ] -
Method
replaceCRLFWithLF()in classTaggedBranchNode: replaces Windows line breaks (CRLF) with Unix line breaks (LF) in all text leaves contained in the branch. -
Methods to convert text leaves into typed values.
Consider the following node:
[bonus 1,000,000 ]Suppose that
TextLeafNodeprovides methodasIntto convert the text into anint. InvokingasInton the above text leaf removes leading and trailing whitespace, removes the commas, converts the remaining text into anintvalue, and returns1000000as result. -
Methods to convert a tree or sub-tree into typed values.
To streamline the conversion of PDML documents (or parts of it) into commonly used in-memory data structures, a PDML implementation can provide dedicated convenience methods/functions.
For example, we often use PDML to store collections — mainly lists and maps (aka dictionaries, associative arrays). Therefore, the PDML reference implementation provides utility class
StringMapUtil, which contains convenience methods to convert PDML trees or sub-trees intoMap<String,String>objects.Here's a file storing three key–value pairs:
File config.pdml[config [ip 192.168.1.1] [port 8080] [timeout] ]You can convert this file into a
Map<String,String>using a single line of code:Map<String,String> config = StringMapUtil.parseFile ( "config.pdml" );parseFile()parses the file into an AST, removes insignificant whitespace (e.g. indents), ensures that the root node only contains tagged text nodes or tagged leaf nodes, and traverses the tree to create and return aMap<String,String>object which you can then use in your application to do whatever you want.
Utility functions/methods executing common whitespace-handling operations provide the following benefits:
-
You can use them in many contexts because they provide a comprehensive set of individual operations that can be combined in many different ways to cover a wide variety of needs.
-
You can apply them to the whole tree, sub-trees, or individual nodes.
-
You can apply different whitespace-handling rules to different sections of a document (e.g. data vs markup sections).
-
The parser is much simpler to implement because there's no need for checking and handling whitespace (less
ifs in the parser source code). -
Documents are parsed faster, because text leaves never need to be tested for whitespace and handled appropriately.
If your application uses only a small part of a document (quite common), you might benefit from a considerable overall performance gain, because the potentially time-consuming whitespace-handling operations are only executed on the data used by your application — they don't need to be executed on the whole tree.
Types
A PDML type (a PDML extension, not part of Core PDML, and not specified here) can be designed to apply customized whitespace-handling rules, applied implicitly when the PDML document is parsed.
Consider the following code:
[birthdate
2000-01-01
]If node birthdate is configured to be of type date, then:
-
Leading and trailing whitespace is removed at parse-time (by functions that are part of the type and implicitly called by the parser).
-
The remaining text is verified to be a valid date in the ISO 8601 format and, if valid, stored in the AST, otherwise an error is generated.
Customized Parsers
If you create a PDML parser for a context where whitespace-handling rules are well-known, then the best option might be to implement the rules in the parser.
However, as stated at the end of section Whitespace Rules, any PDML-compliant parser must preserve whitespace by default. Therefore, a compliant parser must support configuration options to enable whitespace-handling rules explicitly.
Example: Consider a parser that supports configuration option convertCRLFToLF, to convert all occurrences of CRLF into LF. The default value of this option must be false, as required by the specification (i.e. whitespace must be preserved). Hence, convertCRLFToLF must explicitly be set to true to enable the conversion.
Application-Specific Handling
If whitespace-handling rules are very specific (uncommon), then the best approach is usually to implement them in the application that reads the parsed document.
This approach is used in the Practical Markup Language (PML) to implement specific rules, such as: A new paragraph is inserted automatically whenever text is separated by whitespace containing at least two Unix/Windows line breaks.
Line Breaks
As previously mentioned, line breaks in text files (e.g. .pdml files) can be problematic because:
-
Unix/Linux uses
LF, while Windows usesCRLF, making them different. -
Editors and other tools might silently change line breaks (
CRLFtoLFor vice versa).
Reading Operations
Consider the following text in a PDML document:
line 1
line 2The actual line break inserted between the two lines depends on the tool and environment/configuration used to create the PDML document. Most editors running on Windows would (by default) insert a CRLF sequence. If you later edit the document in an editor running on Linux, the line break might silently be changed to LF. Line break changes might also occur due to configuration files such as .editorconfig or .gitattributes, or they might be caused by various tools processing the PDML documents in different environments.
Most modern applications promote EOL neutrality. They tolerate and handle both line break versions equally well, even if they are mixed in a single document — no problem if CRLF is changed to LF, or vice versa.
However, unsupported line breaks can cause strange results or malfunctions. For example, a Unix tool might not work properly if Windows line breaks are present.
To avoid issues, you might want to force the required line break version using character escape sequences. You can force a Windows line break using \r\n:
line 1\r\nline 2... or a Unix/Linux line break using \n:
line 1\nline 2Although usually less user-friendly, escape sequences provide the following advantages:
-
The line break version (Unix or Windows) is clearly shown in editors, and the escape sequences might even be displayed in a different color.
-
Automatic line break changes by editors and other tools won't affect these escape sequences.
Writing Operations
By default, general-purpose PDML writers should:
-
Write line breaks stored in text leaves unchanged.
For example, if a text leaf contains a mixture of Unix and Windows line breaks, then they should be written without transformations, regardless of whether the application runs on Unix or Windows.
-
Write OS-native line breaks for additional line breaks inserted by the writer (e.g. for pretty printing)
Thus, a writer running on Unix writes
LF; on Windows it writesCRLF.
More sophisticated writers can support parameters to customize their behavior, such as:
-
Enforce OS-native line breaks in the output (e.g. a writer running on Unix always writes
LF; on Windows it writesCRLF). -
Always write
LF, even if the application runs on Windows.
Character Tabulations
Character Tabulations (tabs) are often rendered as spaces (typically two to eight spaces per tab). If this is an issue, you can insert the escape sequence \t (instead of just a single tab character), so that tabs and spaces can easily be distinguished.
For example, if an editor is configured to display tabs as two spaces, the text foo bar doesn't tell you if two spaces or a single tab separates foo from bar, whereas foo\tbar clearly shows that a tab is used, and the tab escape sequence might even be displayed in a different color.
Moreover, using \t prevents applications from silently replacing tabs with spaces.
The same goes for sequences of spaces. For example, \s\s (two escaped spaces) would prevent two-space indentation from being replaced by a tab when the editor is set to use tab indentations.
Encoding Binary Data
To encode binary data in PDML documents (e.g. images, audios, and videos), you can use common and portable binary-to-text encoding methods like Base64.
The following example shows a tiny (1x1) PNG image encoded in Base64:
[image
[title Example Image]
[format PNG]
[data
iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAQAAAC1HAwC
AAAAC0lEQVR42mP8/wQAAwAB/AL+j3sAAAAASUVORK5CYII=
]
]About This Document
Copyright
Copyright © 2019-2025, Christian Neumanns.
Everyone is permitted to:
-
Copy and distribute verbatim copies of this document (changing it is not allowed).
-
Create verbatim translations of this document into other human languages and distribute them.
-
Create verbatim conversions of this document into other text formats and distribute them.
Acknowledgments
Many thanks to Tristano Ajmone for his useful feedback to improve this document.
Markup
This document is written in PML, a lightweight markup language based on PDML.
Revision History
-
2025-03-25: version 2.0.0
-
2021-12-03: version 1.0.1
-
2021-06-13: version 1.0.0